Proof-of-Space
This specification defines a secure proof-of-space construction for Plotting and Proving sub-protocols of the Dilithium consensus based on Chia PoS.
Parameters
k: a global memory requirement parameter, currently 20seed: a unique 32-byte seed that determines memory contents (the table values) obtained from the farmer public key, current sector, piece offset within the sector and current history size.PARAM_EXT: a PRNG extension parameter to avoid collisions, currently 6PARAM_M = 1 << PARAM_EXT = 64matching function parameterPARAM_B = 119matching function parameterPARAM_C = 127matching function parameterPARAM_BC = PARAM_B * PARAM_Cmatching function parameter
Table Generation
The table generation comprises computing seven tables . Each table contains ~ entries. The resulting tables are stored in memory.
The first table computes the outputs of , a stream PRNG, over the domain of possible indices . The first table entries are pairs sorted by value rather than by index. Sorting is needed to optimize matching in the calculation of the next table.
To compute the second table, we need to identify pairs of output values in the table that satisfy the matching function . The entries for the second table are computed as outputs of if and only if . Imagine (but it’s more complicated in reality).
To compute the third table, we need to identify pairs of output values in the table that satisfy the matching function . The entries for the second table are computed as if and only if
And so on until the last table.
As a result, each entry in the tables stores the output of the respective and a pair positions = (left_position, right_position) that points to two entries in the previous table such that a matching function is satisfied. The left_position is an integer indicating where the first match value is stored in the table . The right_position is also an integer that indicates where the second match value is stored in the table .
Final PoS Table Format
| Table | Entries | Sorted by |
|---|---|---|
| Table1 | y1=f1(x), x | y1 |
| Table2 | y2, metadata, pos1, offset | y2 |
| Table3 | y3, metadata, pos2, offset | y3 |
| Table4 | y4, metadata, pos3, offset | y4 |
| Table5 | y5, metadata, pos4, offset | y5 |
| Table6 | y6, metadata, pos5, offset | y6 |
| Table7 | y7, pos6, offset | y7 |
The entries in all tables are in the format (y, metadata, positions) with the last three optional. metadata is different from table to table. For the first table, the x values can be considered metadata .
generate
generate(k, seed) → pos_tables
Computes the 7 PoS tables.
- Compute the first table
t_1 = compute_table1(k, seed)and push topos_tables. - Compute each of
t_2, …, t_7, as follows, bytable_number. - Take the previous table (
table_number-1). - For each
entry, separate theyvalues from the table entry into buckets (see illustration) in a sliding manner:-
Define two vectors of entries to hold two buckets of our sliding pair
left_bucketandright_bucket. If this is not the first time we run this loop (we are not at the beginning of the table), set the currentleft_bucketto the previousright_bucketand continue. Otherwise:- Take the entries
entry.ywhile their bucket indexleft_bucket_index = entry.y/PARAM_BCis the same - Place the entry into the first bucket
left_bucket.push(entry).
- Take the entries
-
Take the next entries
entry.ywhile their bucket indexright_bucket_index = entry.y/PARAM_BCis the same asright_bucket_index == left_bucket_index + 1 -
Place the entry into the second bucket
right_bucket.push(entry) -
Find matches in between these buckets as a pair of indices, one from the first and one from the second bucket
(left_index, right_index) = find_matches(left_bucket, right_bucket) -
For each matched pair
(left_entry, right_entry) = (left_bucket[left_index], right_bucket[right_index]), compute the current table’s function(y, c) = compute_fn(table_number, left_entry.y, left_entry.metadata, right_entry.metadata) -
Map the match pair entries
(left_entry, right_entry)positions back from the bucket to their respective positions in the previous table,left_positionandright_position. -
Push to the current table an entry
(ys, metadata, positions) = (y, c, {left_position, right_position}) -
Sort the current table by
(y, [left_position, right_position], metadata)value.chiapossorts the table byy, so the order may differ in our implementation.chiaposuses k-way merge to deal with the fact that table might be too large to store in memory. Since we don’t have this problem we could use a faster algorithm.
-
The resulting pos_tables is a vector containing the 7 tables in order.
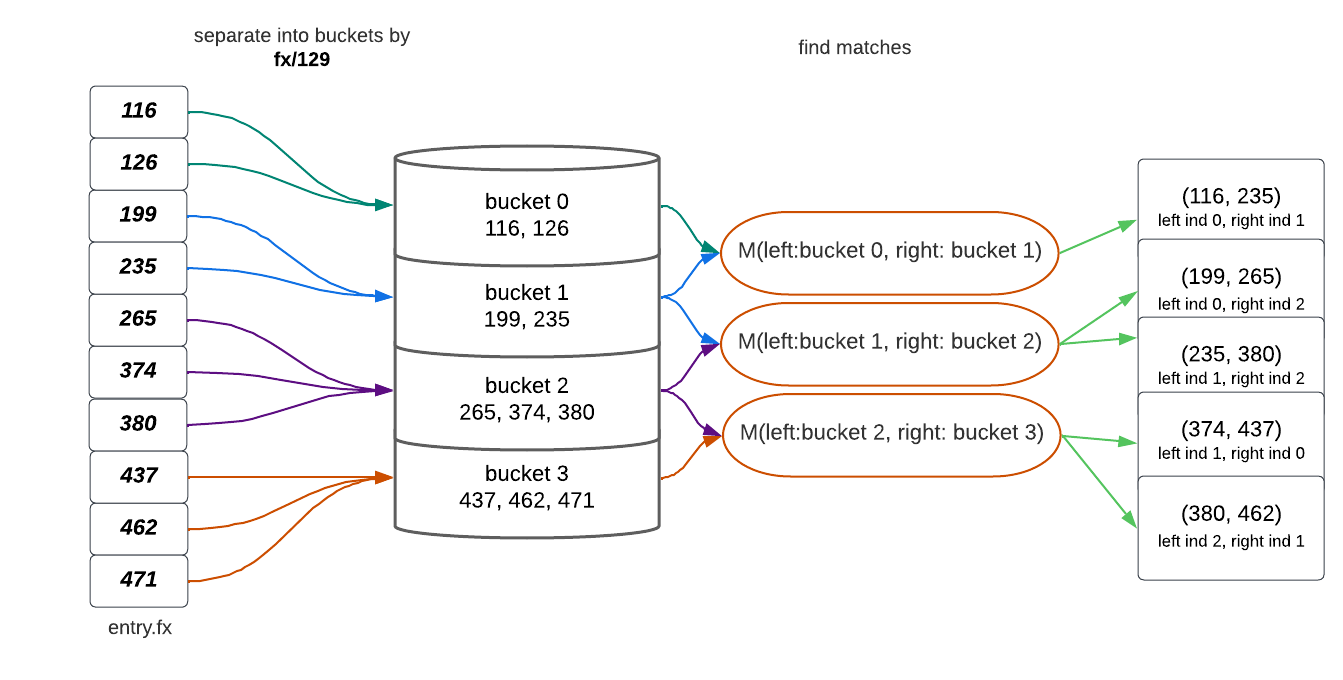
entry.y is sorted, Chia does this sequentially on portions of the table as their tables don’t fit in memory. Notice that 235 and 380 appear in multiple matches, while some numbers don’t have a match.Tables Computation
compute_table1
compute_table1(k, seed) → t_1
Computes the whole table t_1 for all values of x in 0..2^k:
- Initialize ChaCha8 stream PRNG with the given seed
ChaCha8(seed, 0). - Generate
k*2^kbits of PRNG output. Slice it into2^kfxvalues. The output forx=0will be the firstkbits, the output ofx=1will be the nextkbits, and so on. - Append to each
ythePARAM_EXTmost significant bits of the correspondingx. - Push
(y, x)pairs tot_1. - Sort
t_1byy.
- Consider this function a necessary optimization of
compute_f1It is much faster to generate the whole result off1(0..2^k)in one go due to the stream nature of ChaCha instead of computing one by one. chiapos does in batches, since the whole table is too big in their case - The output is extended by
PARAM_EXT(6) bits, sof1(x)takesxof k bits as input and outputs y ofk + 6bits. These 6 bits are the most significant bits of x, added to minimize collisions (birthday paradox). - Sorting is needed to optimize bucketing for
find_matchesin the calculation of the next table
compute_f1
compute_f1(k, seed, x) → y
Computes one value y for a specific x with the first table function. This is a version of compute_table1 but for a single value, necessary for the verifier that does not need to compute the whole table, only the selected `x`` values.
- Compute
skip_bits = x*k - Initialize ChaCha8 stream PRNG with the given seed
ChaCha8(seed, 0). - Seek to the needed point
skip_bitsin the generated keystream. - Set
ythe nextkbits from the keystream. - Append to
ythePARAM_EXTmost significant bits ofx
This is a version of compute_table1 but for a single value, necessary for the verifier that does not need to compute the whole table, only selected x
The output y has length k+PARAM_EXT bits.
compute_fn
compute_fn(table_number, y_in, left, right) → (y, metadata)
- Compute BLAKE3 hash
hash = Hash(y_in || left || right) yishashtruncated tok + PARAM_EXTbits- If
table_number < 4setmetadata = left || right - If
table_number >= 4setmetadatatohashbits[k+PARAM_EXT .. k+PARAM_EXT + metadata_size_bits(table_number)]
metadata_size_bits
metadata_size_bits(table_number) → size
Size of collation metadata corresponding to each table. Extra bits are added to each entry to make Hellman attacks more difficult and ensure that performing space-time tradeoffs is more expensive than honest table generation. For the first table, x value is considered metadata.
k * match table_number {
1 => 1,
2 => 2,
3 | 4 => 4,
5 => 3,
6 => 2,
7 => 0
}
Matching Functions
The matching functions define whether two entries in a table match according to two conditions.
The first condition is that the 2 candidate entries belong to adjacent buckets.
The second condition is quite complex.
Consider an underlying graph of a table: the digraph where each node is an entry, and
an edge exists if that pair of entries is a match. The second condition defines the edges of this graph for parameters PARAM_B and PARAM_C. Each node (entry) of this graph is described with a triplet for (the bucket id of the entry), (entry remainder modulo PARAM_B) and (entry remainder modulo PARAM_C). The edges in the graph are given between two nodes as:
for all 0 ≤ < 64 = PARAM_M
The second condition avoids cycles between inputs if the set is represented as a graph. These cycles can be compressed by saving fewer entries and deriving the rest, representing a potential attack because it would optimize storage (see Cycles Attack in Chia Proof-of-Space Construction v1.1-1). This is also why PARAM_B = 119 and PARAM_C = 127 have those values.
get_left_targets
get_left_targets() → left_targets
Compute possible target matching values left_targets for use in find_matches that fulfill the second condition of the matching function. Note that this only needs to be done once for a set of PARAM_* constants, not on every call:
- Iterate over
parityin0..=1- Iterate over
bcin0 .. PARAM_BC- Calculate
casi/PARAM_C - Iterate over
min0 .. PARAM_M- Calculate
yras((c + m) % PARAM_B) * PARAM_C + (((2 * m + parity)^2 + bc) % PARAM_C); - Set
left_targets[parity][bc][m] = yr
- Calculate
- Calculate
- Iterate over
left_targets can be a global value.
find_matches
find_matches(left_bucket, right_bucket) → vec((left_index, right_index))
Given two buckets with entries (y values), computes which y values match and returns a list of the pairs of indices (left_index, right_index) into left_bucket and right_bucket.
Instead of doing naive pair-wise comparison in we first compute the target values needed to match based on left bucket, then scan the right bucket
-
Iterate over entries in
right_bucketbyright_index.- Create
rmapthat will store a mapping fromrto a list of right bucket positions. - Reduce each entry value to the remainder of its division by
PARAM_BC. To do so, computer_base = (right_bucket[0].y/PARAM_BC) * PARAM_BCand subtract it from each entry’sfxin the right bucket to getr = entry.y - r_base. - Since the same
fxand, as a result, the remainderrcan appear in the table multiple times, in which case they'll all occupy consecutive slots inright_bucket. Hence, all we need to store inrmapis just the positionright_indexof the first appearance of eachrand the number of elements in a map atrmap[r].
yis not unique, so multipleright_indexcan match the samermap[r], but they will all be next to each other, so it is possible to store start index and count rather than dynamically sized vector of indices. - Create
-
Calculate the
parity(0 or 1) of the first entry inleft_bucketas(left_bucket[0].y/PARAM_BC)%2. -
Iterate over entries in
left_bucketwithleft_indexbeing the index of the corresponding entry.-
Reduce each entry value to the remainder of its division by
PARAM_BC. To do so, computel_base = r_base - PARAM_BCand subtract it from each entry’sfxin the left bucket to getr = entry.y - l_base.For each
left_bucketentrym, set a target valuer_targetasleft_targets[parity][r][m]
Check
rmap[r_target]for right indices and collect into pairs of(left_index, right_index). -
-
Return the list of all matching pairs.
Find Quality
Note: Not used in Dilithium, used only for testing the implementation against Chia.
Quality is a 32-byte hash of 2 table entries within the 64-entry full proof. This value is known in the Chia context as a proof quality string however, this naming is irrelevant to our use case as we do not assign any qualitative measure to the outputs of the PoS table.
On the verifier side, the quality is extractable from the full proof.
This value is known in the Chia context as a proof quality string; however, this naming is irrelevant to our use case as we do not assign any qualitative measure to the outputs of the PoS table.
find_quality
find_quality(pos_table, challenge) → proof_quality / None
For a given challenge , sample the pos_table for a proof-of-space quality string the corresponding proof exists at this index, and return None if it doesn’t.
- Take all the entries in the last table
t_7. - Scan the entries’
entry.yvalues to find one where the firstkbits match the firstkbits of thechallenge. If it doesn’t exist, returnNone. - Take the last 5 bits
last_five_bitsof thechallengeto determine the path to follow. - For the matching
entryint_7, iterate backward over tablest_6 .. t_2and backward overlast_five_bits:- If the corresponding bit in
last_five_bitsis 0, read the newentryin the current table at the positionentry.left_position - Else if the corresponding bit in
last_five_bitsis 1, read the newentryin the current table at the positionentry.right_position - Perform the same read in the previous table for the newly found
entry
- If the corresponding bit in
- After step 3 finishes by reaching the second table
t_2, read 2 entries in the first table:- Read the
left_entryint_1at the positionentry.left_position - Read the
right_entryint_1at the positionentry.right_position - Add the left and right entries to the
quality_entriesvector.
- Read the
- For the two
entryinquality_entries, takeentry.xtruncated tokbits and concatenate them together. - Output the 32-byte SHA256 hash of
challenge || left_entry.x || right_entry.x.
- Generally a path to chose between left entry and right entry depends on last bits of challenge (left if 0, right if 1), but we set them all to 0 so we can always follow the entry corresponding to
position
Proving
A proof-of-space for a given challenge is a set of 64 k-bit entries of table t_1.
To find proof, we must see if table t_7 has one or more entries entry.y values where the first k bits match the first k bits of the challenge.
Each satisfying entry in the last table, t_7, points to 2 entries in table t_6. These two entries will point to 2 entries in table t_5 and so on up to table 1. So an entry in the last table will indirectly point to 64 entries in the first table ( ). These 64 entries concatenated are the proof-of-space.
find_proof
find_proof(pos_table, challenge) → proof_of_space
For a given challenge, query the pos_table for a valid full proof-of-space.
- Take all the entries in the last table
t_7 - Scan the entries’
entry.yvalues to find one where the firstkbits match the firstkbits of thechallenge. - For the matching
entryint_7, iterate backward over tablest_6 .. t_1- Set an empty
entries_buffer - Read the
left_entryin the current table at the positionentry.left_position. - Read the
right_entryin the current table at the positionentry.right_position - Add the left and right entries to the
entries_buffervector. - Perform the same read in the previous table for each newly found entry in the buffer.
- Set an empty
- After step 3 finishes by reading all required entries from the first table
t_1, theentries_buffershould have 64 entries. - For each
entryinentries_buffer, take the correspondingentry.xand concatenate them together.
Verification
Verification of the 64-point proof-of-space is performed by evaluating the table functions f1..fn on each x in the proof and checking whether they satisfy the matching function at each step.
To verify a proof-of-space, we need 4 things: the 64 x values in the proof_of_space, the parameter k, the seed, and the challenge_index. The process is more or less the same as table generation, i.e., we compute the same functions but do not generate the entire tables, only a tiny subset. Only the outputs for the x values of the proof are calculated to be able to verify that:
- the outputs
f1..f7satisfy the matching function at each step, - the final output
fnof tablet_7corresponds to thechallenge_index.
Consider an example with four tables. The proof-of-space then consists of values . The verifier will perform the following:
- Compute the outputs of the first table function :
- Verify that the matching function returns a match on each of the following four pairs
- Compute the outputs of the second table function :
-
Verify the matching function returns a match on each of the following two pairs
-
Compute the outputs of the third table function :
-
Verify the matching function returns a match
-
Compute the last table value
-
Verify this value corresponds to our challenge
is_proof_valid
is_proof_valid(k, seed, challenge, proof_of_space) → bool
Verifies whether proof-of-space proof_of_space is valid for the challenge of a table for space_k and seed.
- Split
proof_of_spaceintok-bitx_values. Check thatx_valueshas length 64. - Set 2 empty vectors for
y_valuesandmetadata. - For each
xinx_values:- Calculate the
(y, x) = compute_f1(x)value for each x, and add theyvalue andxmetadata to they_valuesandmetadatavectors, respectively.
- Calculate the
- Iterate over table numbers
2..=7:- Iterate over
y_valuesandmetadatain steps of 2 (for left and right entries) - Create
left_entryandright_entrystructs from they_valuesandmetadata. - Adding
left_entrytoleft_bucketandright_entrytoright_bucketvectors - Check that
find_matchesreturns exactly 1 match. If not, the verification failed. - Calculating
compute_fn(table_number, left_entry.y, left_entry.metadata, right_entry.metadata)and push to buffer. - Set
y_valuesandmetadatato the buffer vectors.
- Iterate over
- Check that the first
kbits ofy_values[0]match the firstkbits ofchallenge_index.
- Verification is fast, but not quite fast enough to be verified in Solidity on Ethereum (something that would enable trustless transfers between chains), since this verification requires blake3 and chacha8 operations.