Subspace: A decentralized database of edge devices
Jeremiah Wagstaff
June 12th 2018
Abstract
A purely peer-to-peer storage network would allow users to have full control over data they generate on the Internet without going through a remote server. Users could host their data directly on devices they already own, while replicating it across other devices on the network in a secure and persistent manner. We propose subspace, a decentralized key-value store with a familiar Javascript API that makes it easy for developers to build apps where users may own their data. Subspace is a peer-to-peer network of edge devices connected over WebRTC that is accessible via any browser, mobile or desktop app. Data is replicated and encrypted at rest in a cryptographically secure schema spread across multiple devices, with a verifiable proof of replication. Hosts pledge free space to the network in return for regular distributions of subspace credits from client apps and users. These agreements are encoded as smart contracts on a distributed ledger secured by Proof of Space consensus. Subspace aims to be a simpler construction of a decentralized storage network focused on developer usability that seeks mass adoption by end users.
Introduction
Services provided over the Internet today are built on the premise of client side applications interfacing with remote servers. Users must pay to access these services, either directly through subscription or transaction fees, or indirectly by signing over the rights to the data they generate. In both cases users must trust service providers to keep their data secure and private. Originally this was done out of necessity. Storage and computation were expensive and constrained by the hardware of the time. Internet connectivity was slow and intermittent. Client devices were incapable of providing these resources on their own and had to rely on servers. But many things have since changed.
-
We have seen a massive consolidation of remote servers, referred to as the ‘cloud’, under a handful of large technology companies. Most services provided over the Internet are either running directly on their hardware, or indirectly on hardware they rent out on the open market. While this has dramatically lowered the barriers to entry for new Internet services, the political and social implications of centralized ownership of the the Internet’s backbone are not attractive.
-
Everyday users have begun to realize that when they trust their data to service providers, they do so at their own risk. Whether it be selling personal data to third parties without their knowledge, providing private information to government agencies, or allowing secure data to fall into the hands of hackers, this trust has been and continues to be breached at an increasing rate.
-
The relative balance of storage and compute power has shifted towards the edge of the network. The peace dividends of the smartphone wars have led to mobile devices reaching parity with traditional desktop computers. We now carry extremely powerful miniature computers with us everywhere we go, that are connected to the internet 24 hours a day, often via WiFi over broadband. These devices have sufficient slack compute and storage power to replace remote servers for a wide array of tasks.
Why pay for services that we can provide ourselves? Why trust others with our data when we don’t have to? Why exchange our data for pennies on the dollar when we can earn the rewards ourselves? Why not rewire the Internet and change the rules of the game, so that we may run applications and host our data on devices we already own?
Many experts believe this to be impossible, or at best impractical. Experts said similar things before BitTorrent proved that a well incentivized and properly engineered Peer-to-Peer (P2P) protocol could work at Internet scale far more efficiently than traditional client-server architecture [1]. In fact, even the largest cloud services provider, Amazon Web Services, operates their data centers using a P2P architecture, albeit under the assumption of trusted hardware [2]. With the introduction of Bitcoin, we witnessed the first example of a P2P system that was able to reach consensus without having to trust the participants in the network [3]. Subspace combines the key elements of these systems, and many others, in order to construct a new model for delivering services and hosting data over the Internet via end user hardware.
Possible Solutions
In a naive approach, users could simply host their data directly on their own devices. Though if the device fails or is lost, the data is gone forever. Furthermore, if the content is popular, the user must bear the burden of the bandwidth required to serve it over the network, while if the device goes offline the data is simply unavailable. Of course we could just replicate the data on all devices that request it, improving persistence and spreading the costs of delivery across all interested hosts. In fact this is how BitTorrent works, as well as more recent approaches based on this premise such as IFPS, SSB, and DAT [4,5,6]. The key limitation of these protocols is that they only replicate popular content, preventing private or obscure data from persisting beyond a single host.
We may also observe that some users will have a surplus of disk space while others will have a surplus of data. If we could establish a tit-for-tat system by which users could trade excess space for excess data, we could incentivize users to host arbitrary data in return for space ‘credits’. These credits could then be used to replicate their own data on to other devices across the network. Of course, we must have strong guarantees that this data remains private and that users will not simply delete it or go offline after replication. The first problem can be handled through a combination of asymmetric and symmetric key cryptography. The second problem is more complex and has been handled many different with varying degrees of success, most notably by Sia, Storj and FileCoin [7,8,9].
Sia is based on per-file smart contracts between a single host and single client, with multiple payments over the life of the contract, and each payment published to the Sia blockchain as a transaction after answering a publicly verifiable challenge with a proof of storage. This leads to high communications complexity during the challenge-response process and requires many transactions to be posted to the blockchain over the life of the contract, making Sia most suited for archival storage of large files. In addition, the proof of storage relies on a compact proof of retrievability, which imposes a high cost of initial computation on the client [10]. Sia is currently live but suffers from extreme usability problems for non-techncial and non-crytpo users.
Storj manages communications through a custom Kademlia Distributed Hash Table (DHT) [11] but still employs a challenge-response method with high communications overhead. Their proof of storage, referred to as a proof of retreivability, requires far less client side computation then Sia, but does not allow for public verifiability, requiring the client to issue challenges directly over the life of the contract. To remove this burden from clients, Storj introduce the “Bridge”, a central server which performs these operations, amongst others, on their behalf. Storj also implements off-chain micropayment channels, significantly reducing the number of transactions posted to the blockchain. Storj has seen many revisions to its architecture and is currently offline pending a new version.
FileCoin is a yet to be implemented proposal to build an incentive layer on top of IPFS for the verifiable storage and retrieval of arbitrary files. It is based on an on-chain storage market and an off-chain retrieval market mediated through storage contracts that establish micro-payment channels between hosts and clients. On-chain consensus is achieved by selecting miners through secret leader election based on a variant of proof of useful work measured by provable storage provided to the network. In the current proposal, FileCoin relies heavily on zero-knowledge succinct non-interactive arguments of knowledge (zk-SNARKs), which are computationally intensive to setup and involve a trusted third party for setup [12]. FileCoin also suffers from yet to be resolved usability issues within IPFS itself. For example, the majority of IPFS nodes run a client written in the Go programming language. For a web browser to access the IPFS network, it must use the IPFS-JS client library, which can only communicate with other IPFS-JS nodes, not standard Go nodes. If we assume the vast majority of FileCoin hosts will be running within a desktop or server environment, files stored on FileCoin would be inaccessible to any web application, unless we rely upon a trusted third party to ‘bridge’ the gap.
It is also worth addressing the often proposed solution of simply storing user generated data on a blockchain directly. On the spectrum of possibilities, this is by far the worst option. A blockchain is a cryptographic data structure that may be used by a decentralized application for the storage and retrieval of arbitrary data across a P2P network of untrusted nodes. However, as they exist today, blockchains are extremely inefficient and simply do not scale. Blockchains are not sharded (every node stores every record), they have very low transaction throughput, and rely on energy intensive Proof of Work (PoW) consensus, making them prone to centralization. Once written, data cannot be removed or changed, and the cost of writing that data is hideously expensive. While there are many proposed solutions to these problems, as of yet none of them have been demonstrated in a production setting.
Witness the effort Ethereum has devoted towards the yet complete Swarm Network, which will allow developers to migrate application state off of the Ethereum blockchain, as well as the bare minimum use of blockchains by competing decentralized app platforms BlockStack and MaidSafe [13,14,15]. On the topic of dApps(decentralized applications) that use these platforms, one is forced to ask, where are they? This only begs the question, why aren’t there any? The answer lies in fundamental usability problems of these platforms. Starting with the developer who must build the dApp, they must understand how blockchains work at least at a basic level, learn a new programming language, and then build their app around a variety of cost and performance constraints. Once these apps are ready to be deployed, they must ask their users to download and install special software such as the Myst, Brave, Beaker, or BlockStack Browser or to add a special plugin to their existing browser, such as MetaMask. Then they ask the user to keep track of a mnemonic seed phrase or even a full private key. It’s like PGP all over again – a great idea with a terrible implementation and little traction among non-technical users.
Core Requirements
Let us imagine a Decentralized Storage Network (DSN) with three classes of participants: ordinary users (clients) who desire to use apps where they can own their data, application developers who want to build those apps, and device owners (hosts) who are willing to host data on behalf of the network in return for ‘space’ credits. Let us also define some key requirements based on the shortcomings of other platforms.
- A focus on usability for developers and users (both hosts and clients)
- A simpler DSN is better than a more complex one
- Blockchains should be used as little as possible
Usability
Usability is the biggest barrier to adoption for decentralized apps for both developers and end users. The easier and more familiar the developer experience, the more decentralized apps we will see. Difficult concepts such as cryptography, P2P networking, distributed computing, and protocol mechanics must be abstracted away to the greatest extent possible. It must have an easy to use developer console and include a local development environment. Developers must be able to easily purchase credits on the network with no prior knowledge of how cryptocurrencies work. The API must be familiar and in a common language that is cross-platform. It must also be configurable to the needs of the app, but with sensible defaults. Specifically, developers should be able to adjust the persistence of data through a replication parameter, allowing them to work with both mutable and immutable objects.
For the end user (client), subspace will have succeeded if the client has no idea they are using a decentralized app. It must provide at least the same guarantees of availability, persistence, and security they have come to expect from centralized web services. It must be designed with the expectation that the browser will be the default client, followed by mobile and then desktop apps. It must work in the browser without any special software or plugins, just a single client side javascript library. Finally, users need not own any subspace credits or be required to run a host device in order to access apps on the network.
For devices owners (hosts), installation and setup should be fast and simple. Mobile hosts should be the initial target market, with a focus on spare mobile devices as they can be left on and connected to WiFi 24/7. A server implementation should also be made available to allow for publicly addressable gateway nodes. Hosts should be able to participate in the network using commodity hardware over internet connections ranging from 3G to broadband, with as little as 10 GB of available storage. The load balancing mechanism in the protocol should be designed such that small hosts are brought to capacity in step with the storage provided by larger hosts, allowing small hosts to remain incentivized by the prospect of earning full rewards for data they store.
Simplicity
All existing and proposed DSNs are based on the notion of a Proof of Storage (PoS), where the host must repeatedly prove ownership of some data over the life of a storage contract. These schemes impose a high communication overhead on the network and result in a large number of transactions posted to the ledger. They do not scale well and the resulting complexity often requires the involvement of centralized services.
Clients need the ability to create a single contract with a single on-chain funding transaction, that allows them to store an arbitrary number of objects of arbitrary size on multiple hosts who may change over the life of the contract. This should only impose a low constant communication overheard on the network that need not involve the client. After funding a data contract, clients must be able to come online at any time to store and retrieve data from the network using only the contract ID. Furthermore, any client must be able to retrieve any object from the network given the object ID, regardless of whether or not they were the original creator of the data. If the data is encrypted, then only clients who have have been added to the keychain or have been provided decryption keys out-of-band will be able to access the underlying data. Any client who can provide a valid digital signature must also be able to update the underlying data. In other words, clients need the ability to create a decentralized permissioned database.
Hosts must be able to pledge a provable amount of space to the network within a single storage contract. Hosts would then be required to store data objects on behalf of any client request that references a valid data contract and continue to return data to any client who has the object ID, so long as the underlying data contract has not expired. Hosts should only receive storage rewards as a fraction of the average network storage over space pledged and the time they remain online. Instead of using a challenge-response procedure involving a proof of storage, maintenance of records should be verified through the normal interaction of the system, as clients retrieve records from hosts. Using an anti-entropy protocol [16], similar to SSB, we may build an eventually consistent picture of the state of all hosts on the network by requiring hosts to gossip signed join and leave proofs, while having a method for nodes to come to consensus when a neighboring host fails. This allows every host to track the accrued time for all other hosts. If we assume a majority of the nodes (51%) to be honest and impose economic penalties for provable dishonesty, we can construct a system that works well even under Byzantine assumptions [17].
A Minimal Ledger
In order to reduce the number of transactions posted to the blockchain we need a way to link client data contracts and host storage contracts into a many-to-many relationship. Existing solutions accomplish this by relying on a trusted third-party, in the form of a central server, or an off-chain network of payment channels based on the lightning network proposal [18]. Subspace relies on an intermediary nexus contract which is the to address for client data funding transactions and the from address for host reward transactions. In terms of ledger transactions, this boils down to one host storage contract per device with a single monthly recurring reward transaction based on the aggregate network utilization and one client data contract, either per application (allowing for multiple users) or per user (allowing for multiple applications), to be renewed on a monthly basis through a funding transaction. Renewal periods should be configurable and subject to the ledger transaction fees tolerable by the participant.
Previous DSNs have relied on Proof of Work consensus, which leads to a high cost of mining and is prone to centralization. Proof of Stake has been proposed as an alternative zero-cost mining solution [19] but results in a complex consensus protocol with a much larger attack surface [20]. PermaCoin [21] introduced the concept of a useful proof of work, archival data storage, as a means of securing blockchains and this idea has been extended in the FileCoin proposal with the addition of a under a secret leader election model that more closely resembles Proof of Stake.
Notably, Burst [22] was the first production blockchain to introduce the notion of Proof of Space consensus, whereby a provable amount of disk space is seeded with solutions, which may then be submitted in response to a block challenge. This replaces the notion of mining with farming, a more environmentally friendly alternative that is far less prone to centralization since proofs of space are not computationally parallelizable and the amount of unused disk space on the Internet is massive. Unfortunately proof of space alone has been proven insecure in that it allows for grinding and history rewriting attacks [23]. Fortunately, two capable teams are actively working to build a secure Proof of Space based ledger. Chia combine a proof of space with a Proof of Time [24], in the form of a Verifiable Delay Function that ensures sufficient wall clock time has elapsed to prevent the aforementioned attacks. SpaceMint ensures any farmer may only generate one unique Proof of Space per block, and evaluates the quality of that proof as a function of a short sequence of previous blocks [25].
It is worth noting that neither Chia nor SpaceMint propose to use Proofs of Space in the sense that the space provided is ‘useful’ as it is in a DSN. Instead, they simply wish to create a better Bitcoin, in the form of a more secure and more decentralized financial ledger. However, this method of consensus could be extended for any blockchain based application. In fact, it is a very pragmatic match for a DSN. In a verifiable DSN, each host should provide an initial proof of space, proving they actually have the disk capacity they are soliciting on the network. Farmers on a Proof of Space blockchain also begin with an initial proof of space and seeding process, albeit in a non-interactive fashion. The two could be combined into a single step, making every host a potential farmer. A host could then choose to reserve its space solely for farming, in the hope of winning a block reward, or rent out the free space on the network in return for more regular but less valuable hosting rewards. In fact, a node could perform both roles, simply overwriting its available solutions with hosted data over time. This provides an incentive for high-capacity nodes to focus on farming while low-capacity nodes can focus on hosting.
Defining Subspace
Subspace is a decentralized database (SSDB) that is massively sharded amongst a network of internet enabled host devices that may include mobile phones, tablets, desktop computers, and traditional servers. A javascript client library with a simple put(), get() Application Programming Interface (API) is provided to developers, allowing them to store and retrieve data inside any web, mobile, desktop, or server-side app. Anyone who uses these apps has full ownership and control of the data they generate, through their private key. Each record stored in SSDB is guaranteed to persist with a replication factor (R) in a manner that is self-healing as hosts leave the network. Space utilization is load balanced across all hosts proportional to the amount of space pledged.
Node Identities: Each node maintains a persistent cryptographic identity through an ED25519 PGP key pair. Private keys are stored on the device and public keys are shared with all other nodes on the network. A node’s payment and routing address are the SHA256 hash of its public key. The PGP protocol was selected for its ability to handle multi-key encryption, allowing for the creation of fine grained permission schemes for SSDB records.
Transport Layer: Nodes form a relay network of stateful WebRTC data channels inspired by Kademlia, allowing them to communicate with each other using only the node ID [26]. The problem of network address translation (NAT) is handled by implementing the ICE protocol in WebRTC over gateway nodes. These publicly addressable nodes may relay signaling information between devices behind NATs, allowing for direct P2P connections via hole punching techniques [27]. WebRTC also allows for cross-platform connectivity and is the only means of connecting browsers directly to host devices.
Gossip Protocol: Nodes disseminate signed gossip between their neighbors in the relay network including join, leave, failure, fault, and ping messages. These messages are used to disseminate updates to the membership pool, an eventually consistent local hash table maintained by all nodes. The membership pool tracks the current status, uptime, and public key of each node. This allows nodes to evenly distribute put(), balance(), and replicate() requests across the network through a Random Peer Sampling (RPS) algorithm, quickly verify digital signatures, and come to consensus on the uptime for any given node.
Distributed Hash Table: A modified sloppy Kademlia DHT based on WebTorrent is layered on top of the WebRTC relay network and serves as a distributed index for SSDB [28, 29]. Given a record key the DHT will return an array of node IDs who currently hold that record. Kademlia is extended to only allow nodes to announce records given a valid put() or replicate() request. Records do not expire until any node can provide a valid leave, failure, or fault message. Hosts coordinating a put() request may also multi-announce ownership of records. Clients holding records in their LRU cache may still announce records with a traditional expiry period.
Record Schema: SSDB records are stored locally on each node using a cryptographic encoding schema inspired by the BEP-44 specification, where the key for an immutable record is the SHA256 hash of the value, while the key for a mutable record is the SHA256 hash of a unique ECDSA public key generated specifically for that record [30]. Each record is JSON encoded and includes a data field up to 1 MB in size. Regardless of the encoding format all records are digitally signed by the record owner and must reference a valid data contract ID.
Record Encryption: Content is encrypted by default with an AES 256 symmetric key that is unique to this record and included in the record schema. The symmetric key is asymmetrically encrypted using the private key of the record owner (for immutable records) or the private key of the record (for mutable records), and the public keys of any other identities that that the owner would like to share the data with. Identities may be the key of other nodes or any arbitrary group schema that can be embedded into an SSDB record. It is also possible to specify fine-grained access control with read, write, and admin privileges for each identity.
Distributed Ledger: While SSDB records are stored off-chain in a series of local shards on each node and the record-node mapping is stored on the DHT, we still need a secure method of accounting for subspace credits between peers. This is tracked in the Subspace Credit Ledger (SSCL), a blockchain maintained by Proof of Space consensus, but otherwise similar to Bitcoin. SSCL is also stored on SSDB as a series of linked immutable records.
Smart Contracts: SSCL shares the BitCoin smart contract language, Script, allowing for the creation of storage contracts to mediate payments between hosts and clients in the simplest manner possible. Specifically, host storage contracts, client data contracts, and the subspace nexus contract are included in the protocol. Developers are encouraged to extend these default contracts with their own schemes.
Host Storage Contracts
Hosts pledge free disk space and agree to store data on behalf of the network in return for subspace credits. When a new device comes online the owner will generate a storage contract specifying the amount of disk space and the reward interval. This space is seeded using the host’s private key, yielding a dual purpose Proof of Space (PoS). This proof of space is embedded within a storage contract that is self-hosted on SSDB and gossiped to farmers for validation and inclusion as a transaction in the next block of the ledger.
Once published, the host will broadcast it’s availability for puts() and gets() by gossiping a join message to it’s immediate neighbors that references this transaction. As the join spreads through the network, each node will add the host to its membership pool, an in-memory local hash table which tracks the current state of all hosts in the network. The membership pool tracks the longevity of hosts and is used to validate payment requests submitted by hosts at the end of their contract storage interval. As hosts go offline and reconnect, their accrued time is adjusted. If hosts remain offline within a timeout period greater than their contract interval, nodes will automatically drop them from the membership pool.
The integrity of the subspace network is built on the premise of random interaction leading to an eventually consistent and even distribution of records. In order for this to work, each node must know about a significant fraction of other nodes on the network and utilizes the RPS algorithm to find other nodes when writing, replicating, or balancing records across SSDB. While the network is small (less than 1M nodes), it is feasible for each node to maintain an eventually consistent picture of the entire network. As the network grows larger, it would be possible to separate the network into buckets or sectors with each peer knowing more about peers closer to its ID namespace and less about peers further away, following the general approach of K-Buckets and XOR distance used in Kademlia.
Client Data Contracts
In order for host to accept a put() request on behalf of the network, the request must reference a valid data contract. Anyone may create a data contract by submitting a valid data transaction to the SSCL. This transaction encumbers subspace credits into an agreement between the contract holder and the subspace network. The network will agree to store an amount of data based on the Cost of Storage (CoS) published in the last block in return for the ability to pay these credits out to hosts. Each contract will specify a duration, reference a valid SSCL address with sufficient funds and link to a contract profile stored on SSDB as a mutable record, which is used to track the contract balance.
Developers building apps utilizing the subspace network must decide how data hosting costs will be paid. Users who are also subspace hosts or farmers may wish to pay their own hosting costs and should be given the option to login to the app using their subspace private key before linking to a personal data contract. However, to allow any user to access their service, regardless of their knowledge of, or access to, subspace credits, developers should create app data contracts to cover the costs of hosting. Each app contract will have an associated Hierarchical Deterministic (HD) wallet used to manage access to contract funds in a permissioned manner [31]. As new users are on-boarded, the app would generate valid subspace identities for them, which would be stored on SSDB. It would be at the discretion of the app developer to decide if or how to manage payments in a fiat currency for access to their app. Example schemes will be provided in the subspace developer documentation and may later be abstracted into a separate client library, subspace-auth.
Client data contract funding transactions will always specify the to, or payment address, as the subspace nexus contract. The nexus contract allows for simple aggregation and redistribution of credits by farmers to hosts and provides a fixed cost of storage over the life of the contract. Conceivably, clients could instead pay long-lived hosts directly for storage, although the additional transaction costs and maintenance requirements would make this process unattractive for most use cases. Since subspace is an open network built on an open source protocol, developers and entrepreneurs are free to experiment with alternate management schemes.
Storage Workflow (Put Requests)
When a client app needs to store data on the network, it will submit a put() request. The data itself is encoded in a cryptographic schema following BEP-44 and encrypted using a record specific symmetric key controlled by the client’s private key. The put() request will include the encoded data and must reference a valid data contract. The client will select a coordinator host at random from its list of known hosts (via the membership pool) and send the put() request over WebRTC. The host will fulfill the request optimistically, storing the record in their local shard, before initiating an asynchronous contract validation and replication procedure. The client will receive an initial acknowledgement from the host and may proceed under the assumption that they will soon receive a full acknowledgement if an honest put() request was sent.
The host will then locate the data contract in SSDB and verify it has space available and that the requestor has write permissions for the contract. If the request is invalid, the host will simply delete the data and return an invalid response to the client. If the request is valid the host will begin replicating the data onto R-1 other hosts, where R is the replication factor specified in the data contract. All hosts will store the data using a verifiable time-delay encoding function, using the data and their public key as the input. This function is configured such that it takes much longer to encode the data than it would for a reasonable get() request to be answered, preventing outsourcing attacks by ensuring each host maintains a unique physical copy of the data. The encoded data becomes a Proof of Replication (PoR) which the client may efficiently validate [32, 33, 34]. Each host will also add a transaction receipt signed by the client to their local, self-hosted storage profile.
Once all hosts have returned a valid PoR to the coordinator, it will multi-announce the key (for all hosts) on the DHT and forward the PoRs to a host holding the client’s off-chain contract state. The contract host will validate each PoR, then increment the contract balance and append the key to the contract index. Once the coordinator receives validation, they will complete the request by sending an acknowledgment to the client. Clients will maintain connections to the same coordinator over a timeout enforced app session in order to reduce the latency and overhead of subsequent requests.
Retrieval Workflow (Get Requests)
Importantly, any client or host may submit a get() request at no cost in subspace credits. This is in contrast to previous DSN schemes where get() requests either include or unlock funds associated with the storage of a record. These schemes work under the assumption that only the client who stored the data will request it, or where all clients have a balance of space credits they may use for requests. This presents a challenging user experience and heavily constrains application use cases. Imagine if every time you visited a website on the public Internet, you had to attach a micropayment to download the page. Get() requests must be free in the setting of an open network.
Of course, it is unrealistic to expect only a handful of hosts, as defined by the replication factor, to serve all requests for a given record, especially if that record is popular. To get around this dilemma, subspace follows the example of other P2P protocols by adding social replication as the default behavior. This means that any node who requests some data will also announce and serve this data over the network. The more popular the data, the more nodes there will be to serve it, with requests evenly distributed amongst all eligible nodes. These records are written to a local Least Recently Used (LRU) cache and are announced on the DHT under a traditional expiry method.
Any client connected to the subspace network may submit a get() request given a record key, beginning with a DHT lookup. The lookup will return a list of node IDs where the record is currently being held. Clients will then select one host to act as the request coordinator, whom they will initiate a direct WebRTC connection with before requesting the record. The client will then validate the record based on it encoding schema and ensure the time-delay encoding is unique to the host. Developers working with latency sensitive collaborative applications may require the coordinating host to retrieve and arbitrate state between all replicas of a record, either merging them prior to delivery or submitting all replicas to the client for arbitration.
Host Incentives
If the host does not have the data, they may attempt to fool the client by generating some false data on demand or quickly retrieving the record from another host. Clients will validate immutable records by checking the hash and mutable records by checking the signature, thwarting the first attack. Since the data is uniquely time-delay encoded, it would be impossible for them to retrieve, decode, and recode a valid record within the allotted timeout period. In either case, the client will then be able to submit the false response (signed by the host) to the host’s profile holder who will then decrement the accrued time for the host by 24 hours, impacting their hosting rewards. PoR also prevents hosts from conducting a sybil attack, in which the host creates multiple proofs of space under multiple identities and tries to collect rewards for all storage contract while only actually writing the data once.
Hosts will continue to serve put() and get() requests from clients as long as they remain online. If a host goes offline as part of a graceful shutdown, for example if the device owner closes the subspace app, the host will send a signed leave message to its neighbors, which will be gossiped throughout the network. Every node who receives the leave message will validate the signature before stopping the time counter for the given host and beginning the replication process for all keys stored by that host. If the host fails, or appears to fail, either through a WebRTC connection timeout or failure to respond to a new connection request, neighboring hosts will attempt to relay ping messages through other hosts. If the neighbors are unable to receive a valid response from the failed host, or received a signed message through an intermediary hosts, they will deem the host a failure and begin gossiping a failure message which will also stop the clock for the given host.
Farming the Ledger
The SSCL is very similar to Bitcoin but with one key difference. Instead of using Proof of Work, it uses Proof of Space [35] to decide who may add the next block to the chain. Every block in the ledger includes a challenge, derived from some number of previous blocks. Farmers compete to solve this challenge, earning the right to add the next block to the chain and receiving the block reward. Recall that farmers initially seed their free disk space with a set of unique solutions mathematically linked to their persistent private key. In a Proof of Space ledger, farmers propose new blocks based on their best solution to the challenge. Any node can quickly evaluate the accuracy of a solution and whether it was in fact generated by the farmer, by checking their proof of space. The more space a farmer provides, the more solutions they will have and the more likely they are to earn the right to add the next block to the ledger. While any host may be a farmer, as they store data to earn hosting rewards, they will overwrite their solution space and decrease their chances of winning a block reward.
To create a new block, a farmer first creates the coinbase transaction, minting new subspace credits and transferring them to their own address as their block reward. Next, the farmer will add all valid Pay to Public Key Hash (P2PKH) transactions, host storage contracts, and client data contracts to the block. Now the farmer must validate all host payment requests and compile them into a single nexus transaction. Then the farmer will compute the CoS for the block, based on aggregate storage pledged and data reserved. Finally, the farmer will publish the block as an immutable record on SSDB and gossip it to all neighboring nodes. Nodes will only keep the block if it is the most valid solution they receive for the current block challenge. They will also check to ensure that the solution is a valid proof of space for the farmers public key, that all of the transactions are valid and that the CoS was calculated correctly before replicating the block and announcing ownership on the DHT.
Calculating the Cost of Storage (CoS)
CoS is a concept similar to the unspent transaction output (UTXO) in Bitcoin but as it relates aggregate space, data, and credits on the network. Any node may compute the CoS for a given block if they have a full copy of the SSCL. It is simply the ratio between the total supply of subspace credits and the difference of all space pledged by hosts and all data reserved by clients. This can be expressed as:
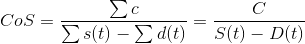
C, the total credit supply, is simply the sum of all coin base transactions in the ledger. S(t), the total space-time pledged by all hosts, is calculated by summing the space pledged and time remaining on all valid host storage contracts that have been published to SSCL. A contract is valid if the host submitted a payment request when the last contract interval expired. s(t), the total remaining space-time for any given host is calculated in byte-seconds by computing the product of the space pledged and the time remaining until the current interval expires. D(t), the total data-time reserved by all clients, is calculated by summing the data reserved and time remaining on all valid client data contracts that have been published to the SSCL. It is noteworthy that this number reflects the reserved space on the network, not the actual amount of space holding client data, which has no relevance to the cost of reserved storage. d(t), the total remaining data-time for any given client contract, may be calculated in byte-seconds as the product of the data reserved in bytes and the time left on the contract in seconds. Subtracting D(t) from S(t), we are left with the total amount of space-time left on the network. We may then determine the cost of a unit of space-time by computing the fraction of total space-time over the total credit supply. This returns a constant in credits per byte-second, which we may convert to a more familiar credits per gigabyte-month.
Each block will have a different CoS, as hosts and clients churn, and the value of contracts decreases over time, affecting the ratio between available space and data reserved. The CoS serves two purposes. First, it allows clients to purchase a fixed amount of space at a fixed price over a given period, ensuring reliable access to their data. Second, it allows farmers to reward hosts fairly for data they store without having to manually track storage on each host or manage a secondary network of micropayment channels. The CoS is not the same thing as the Price of Storage, which is the exchange rate between fiat currency and subspace credits, which will ultimately be decided by the market.
Calculating the Nexus Payment
Each block has a single nexus transaction with as many outputs as there are valid payment requests, one for each host whose payment is due. Once the specified interval for a host storage contract has been reached, the host may submit a payment request to the transaction pool for validation by farmers. The request must include the contract ID and the hash of the last block with a valid signature. Farmers will compute the payment for each valid request and include it as an output in the nexus transaction. Host payments are a product of the average CoS over the contract interval, the average utilized space, and the percentage of time the host was online, expressed as:
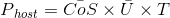
Average CoS is obtained by summing the CoS published in each block over the contract interval and dividing by the number of blocks. This will only have to be computed once for each nexus transaction as all hosts will be on the same 30 day contract interval, and can be easily adjusted as a rolling sum as new blocks are added to the ledger. Average utilized space reflects the amount of data actually held by the host, but is computed from aggregates rather than explicitly tracking for each host. We may do this because the network is self-balancing in a manner that is proportional to the size of each hosts storage contract, with small hosts being filled to capacity before large hosts. Average utilized space is computed by sequencing all host storage contracts in the ledger from smallest to largest and then filling them up to the network average. This operation only needs to be performed once for each nexus transaction and may also be incrementally adjusted between blocks. The uptime rate is obtained by checking the LHT to see the accrued uptime for the host for this period.
Implementation Plan
Subspace, Inc. will bootstrap the network by operating a small number of publicly addressable gateway nodes. These nodes will pre-farm the SSCL to create a reserve of subspace credits for the initial exchange. Subspace, Inc. will host and manage this exchange as a separate service, acting as a Money Services Broker (MSB), in compliance with the current financial regulatory environment. Importantly, purchasing credits on the exchange is not a prerequisite for participation in the subspace network. Anyone may join the network as a host or farmer and earn credits themselves. The purpose of the exchange is to provide a painless experience for ordinary developers and users who simply wish to reserve storage on the network. As the supply of subspace credits grows, the exchange will transition into a decentralized marketplace where hosts, farmers and clients may freely exchange credits for fiat or other crypto-assets. Importantly, subspace credits will not be offered on popular crypto-asset exchanges, in order to discourage speculative investment, which would only serve to artificially raise the price of credits with negative impacts on the practical usability of the network.
Subspace, Inc. will also manage the nexus contract, taking a small transaction fee on all host payments. The nexus contract would be backed by the Subspace Credit Reserve and entail a degree of trust that Subspace, Inc. has the best interests of the subspace network at heart. Anyone is welcome to package and distribute competing implementations, which may manage hosting rewards with different transaction fees and with varying degrees of centralization. It is important to stress that subspace is an open network, in the spirit of the Internet, with no trusted central authority or gatekeeper. Anyone may run a gateway node with a public IP address. Anyone may act as a host or farmer by installing the subspace protocol on their hardware. Anyone may create a subspace app using the open source client library. And anyone may store data on the network using subspace credits. In this manner, subspace is more akin to a public utility. It could outlive any one company and might lead to the creation of many more, if not an entire industry.
While the range of application use cases are conceivably very broad, early efforts will focus on developers in the decentralized and cryptocurrency space. It is expected that some of the earliest apps on the subspace network will be cryptocurrency wallets, decentralized asset exchanges, and decentralized social networks. In fact, the initial subspace mobile implementation will be a combination of these. It will present a social wallet to the user, with an experience similar to Venmo. Anyone who installs the app on their device will be able to host data, act as a farmer, and transfer subspace credits to other users with social profiles that would be discoverable across a range of privacy settings. Of course, all application state would be replicated on SSDB.
Future Work
The subspace platform is built on three main pillars:
- The core protocol, written in javascript and compatible with both Node JS and browser runtimes
- Device specific implementations of the protocol that allow hosting & farming across hardware platforms
- A client-side API or SDK, also written in javascript, that allow apps to utilize the subspace platform
The initial focus of the platform will be a key-value store (SSDB) powered by spare mobile devices and accessible from the browser. Over time, the scope of all three pillars may be expanded. The intended goals for host device implementations and client side accessibility have already been outlined, and are obtainable in the near term given the portability of javascript. In time, the client SDK would also be expanded beyond javascript to work natively in many different languages and within popular frameworks. The functionality of the reference app would also be expanded as new primitives and services are added to the the underlying protocol. This raises a more interesting question of how the core protocol could be extended beyond a simple key-value store.
Initially, SSDB could be abstracted out into a file system (SSFS), by chunking large files across multiple records and keeping an index record. An SSDB record could also be used to store application code, which could be remotely executed on a host device, yielding something between a smart contract and a serverless function (S3C). Once subspace includes the key primitives of a database, file system, and compute platform, we can begin to build more interesting services on top of it. These might include: a global authentication system, using a public-private key pair (SS-Auth); a content delivery network for hosting static assets (SS-CDN); a package manager for software libraries (SS-NPM); a decentralized domain name service (SS-DNS); or even a permanent, immutable storage platform for any blockchain (SS-DLT). This might lead to something like a decentralized version of Amazon Web Services.
References
[1] Bram Cohen. Incentives build robustness in BitTorrent In Proc. of IPTPS, 2003. URL: http://www.bittorrent.org/bittorrentecon.pdf
[2] G. Decandia, D. Hastorun, M. Jampani, G Kakulapati, A. Lakshman, A. Pilchin, S. Sivasubramanian, P. Voshall, and W. Vogels. Amazon, Seattle. Dynamo: Amazon’s highly available key-value store In Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles (2007), ACM Press New York, NY, USA, pp. 205–220. URL: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[3] Satoshi Nakamoto. Bitcoin: A Peer-to-Peer Electronic Cash System 2009 URL: https://bitcoin.org/bitcoin.pdf
[4] Juan Benet. IPFS - Content Addressed, Versioned, P2P File System (DRAFT 3) 2014. URL: https://ipfs.io/ipfs/QmR7GSQM93Cx5eAg6a6yRzNde1FQv7uL6X1o4k7zrJa3LX/ipfs.draft3.pdf
[5] Secure Scuttlebutt. URL: https://ssbc.github.io/scuttlebutt-protocol-guide/
[6] Maxwell Ogden, Karissa McKelvey, Mathias Buus Madsen. Code for Science. Dat - Distributed Dataset Synchronization And Versioning May 2017 (last updated: Jan 2018) URL: https://github.com/datprotocol/whitepaper/raw/master/dat-paper.pdf
[7] David Vorick, Luke Champine. Sia: Simple Decentralized Storage November 29, 2014 URL: https://sia.tech/sia.pdf
[8] Shawn Wilkinson, Tome Boshevski, Josh Brandoff, James Prestwich, Gordon Hall, Patrick Gerbes, Philip Hutchins, Chris Pollard, Vitalik Buterin Storj: A Peer-to-Peer Cloud Storage Network December 15, 2016 v2.0 URL: https://storj.io/storj.pdf
[9] Protocol Labs Filecoin: A Decentralized Storage Network January 2, 2018 URL: https://filecoin.io/filecoin.pdf
[10] Hovav Shacham, Brent Waters. Compact Proofs of Retrievability ASIACRYPT ‘08 Proceedings of the 14th International Conference on the Theory and Application of Cryptology and Information Security: Advances in Cryptology Pages 90 - 107, Melbourne, Australia — December 07 - 11, 2008 URL: https://cseweb.ucsd.edu/~hovav/dist/verstore.pdf
[11] Petar Maymounkov, David Mazières. Kademlia: A Peer to Peer Information System Based on the XOR Metric In: Druschel P., Kaashoek F., Rowstron A. (eds) Peer-to-Peer Systems. IPTPS 2002. Lecture Notes in Computer Science, vol 2429. Springer, Berlin, Heidelberg. 2002. URL: https://pdos.csail.mit.edu/~petar/papers/maymounkov-kademlia-lncs.pdf
[12] Eli Ben-Sasson, Alessandro Chiesa, Eran Tromer, Madars Virza. Succinct Non-Interactive Zero Knowledge for a von Neumann Architecture May 19, 2015 URL: https://eprint.iacr.org/2013/879.pdf
[13] Vitalik Buterin. Ethereum: A Next-Generation Smart Contract and Decentralized Application Platform URL: https://github.com/ethereum/wiki/wiki/White-Paper
[14] Muneeb Ali, Ryan Shea, Jude Nelson, Michael J. Freedman. Blockstack Technical White Paper Technical Whitepaper Version 1.1 October 12, 2017 URL: https://blockstack.org/whitepaper.pdf
[15] SAFE Network. A SAFE Network Primer: An introductory guide to the world’s first fully autonomous data network. February 2018 URL: https://www.maidsafe.net/docs/Safe%20Network%20Primer.pdf
[16] Robbert van Renesse, Dan Dumitriu, Valient Gough, Chris Thomas Amazon.com, Seattle Efficient Reconciliation and Flow Control for Anti-Entropy Protocols LADIS ‘08 Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware Article No. 6 2008 URL: https://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf
[17] Leslie Lamport, Robert Shostak, and Marshall Pease. SRI International. The Byzantine Generals Problem ACM Transactions on Programming Languages and Systems, Vol. 4, No. 3, July 1982, Pages 382-401. URL: https://people.eecs.berkeley.edu/~luca/cs174/byzantine.pdf
[18] Joseph Poon, Thaddeus Dryja. The Bitcoin Lightning Network: Scalable Off-Chain Instant Payments January 14, 2016 DRAFT Version 0.5.9.2 https://lightning.network/lightning-network-paper.pdf
[19] Vitalik Buterin, Virgil Griffith. Casper the Friendly Finality Gadget 2017 URL: https://arxiv.org/abs/1710.09437
[20] Bram Cohen. Chia Network. Stopping Grinding Attacks with Proofs of Space Technical Talk https://www.youtube.com/watch?v=2Zlcgt8FVz4
[21] Andrew Miller, Ari Juels, Elaine Shi, Bryan Parno and Jonathan Katz. Permacoin: Repurposing Bitcoin Work for Data Preservation IEEE Security & Privacy (Oakland), May 2014 URL: http://soc1024.ece.illinois.edu/permacoin.pdf
[22] Burstcoin. URL:http://burstcoin.info
[23] Hamza Abusalah, Joel Alwen, Bram Cohen, Danylo Khilko, Krzysztof Pietrzak1, and Leonid Reyzin. Beyond Hellman’s Time-Memory Trade-Offs with Applications to Proofs of Space In: Takagi T., Peyrin T. (eds) Advances in Cryptology – ASIACRYPT 2017. ASIACRYPT 2017. Lecture Notes in Computer Science, vol 10625. Springer, Cham URL: https://eprint.iacr.org/2017/893.pdf
[24] Bram Cohen and Krzysztof Pietrzak. Simple Proofs of Sequential Work In: Advances in Cryptology – EUROCRYPT 2018, pp.451-467 URL: https://eprint.iacr.org/2018/183.pdf
[25] Sunoo Park, Albert Kwon, Georg Fuchsbauer, Peter Gazi, Joel Alwen and Krzysztof Pietrzak. SpaceMint: A Cryptocurrency Based on Proofs of Space Financial Cryptography and Data Security 2018. URL: https://eprint.iacr.org/2015/528.pdf
[26] Austin Middleton. Peer-Relay Library URL: https://github.com/xuset/peer-relay
[27] Bryan Ford, Pyda Srisuresh, Dan Kegel. Peer-to-Peer Communication Across Network Address Translators Proceeding ATEC ‘05 Proceedings of the annual conference on USENIX Annual Technical ConferencePages 13-13. Anaheim, CA — April 10 - 15, 2005 URL: http://www.brynosaurus.com/pub/net/p2pnat/
[28] Arvid Norberg and Andrew Loewenstern. BitTorrent.org BEP-5: DHT Protocol 2008 URL: http://www.bittorrent.org/beps/bep_0005.html
[29] Feross Aboukhadijeh and many others. BitTorrent-DHT Library URL: https://github.com/webtorrent/bittorrent-dht
[30] Arvid Norberg and Steven Siloti. BitTorrent.org BEP-44: Storing arbitrary data in the DHT 2014 URL: http://www.bittorrent.org/beps/bep_0044.html
[31] _BIP-32: Hierarchical Deterministic Wallets URL: https://github.com/bitcoin/bips/blob/master/bip-0032.mediawiki
[32] Juan Benet, David Dalrymple and Nicola Greco. Protocol Labs. Proof of Replication Technical Report July 27, 2017 URL: https://filecoin.io/proof-of-replication.pdf
[33] Arjen K. Lenstra and Benjamin Wesolowski. A random zoo: sloth, unicorn, and trx Cryptology ePrint Archive, Report 2015/366. URL: https://eprint.iacr.org/2015/366.pdf
[34] Ben Fisch. Proof of Replication using Depth Robust Graphs Technical Talk at Blockchain Protocol Analysis and Security Engineering 2018. https://www.youtube.com/watch?v=8_9ONpyRZEI
[35] Stefan Dziembowski1, Sebastian Faust, Vladimir Kolmogorov, and Krzysztof Pietrzak. Proofs of Space URL: https://eprint.iacr.org/2013/796.pdf